Who is Anna?
You are Anna!
Archivisti di nome, bibliotecari per definizione, volontari per attività, anticonformisti per loro affermazione, pirati per necessità: il team di Anna presenta il suo progetto come “la più grande biblioteca veramente aperta nella storia dell’umanità”. La biblioteca (o archivio?) di Anna, alla data odierna conta oltre 650.000 libri, scaricati ogni giorno. Facendo una stima approssimativa della circolazione della più grande biblioteca pubblica del mondo, la New York Public Library, che è di circa 30.000 copie al giorno, notiamo che rappresenta solo il 10% della distribuzione di Anna. Al momento della pubblicazione di questo numero, l’Archivio di Anna raccoglie più di 40 milioni di libri e circa 100 milioni di articoli scientifici. Questi dati appaiono sufficientemente significativi per meritare un’indagine sul ruolo di Anna nel panorama mondiale della circolazione dei libri e del diritto d’autore.
Potrebbe essere facile liquidare Anna come una pirateria da poco, un “trucchetto” che professori condiscendenti girano a bassa voce ai loro studenti, ma in realtà è impossibile considerare Anna come una semplice deviazione tra le tante nella nostra vita di regole. Anna merita indubbiamente un trattamento e un riconoscimento migliori. L’Archivio di Anna si configura come un tentativo di diventare un nuovo tipo di biblioteca, una biblioteca che partecipa al dialogo sulla conoscenza e che cerca di cambiare le regole della sua circolazione.

La biblioteca di Anna: progetto utopico o semplice pirateria?
Possiamo affrontare il fenomeno di Anna da due punti di vista: attraverso la descrizione dei suoi compiti e dalla storia delle cosiddette “biblioteche ombra”. Per quanto riguarda il primo, Anna articola molto chiaramente l’essenza della sua attività: il team afferma che si tratta di un progetto senza scopo di lucro con due obiettivi:
1) conservazione – fare un backup di tutta la conoscenza e la cultura dell’umanità;
2) accesso – rendere conoscenza e cultura disponibili a chiunque nel mondo (https://annas-archive.org/faq).
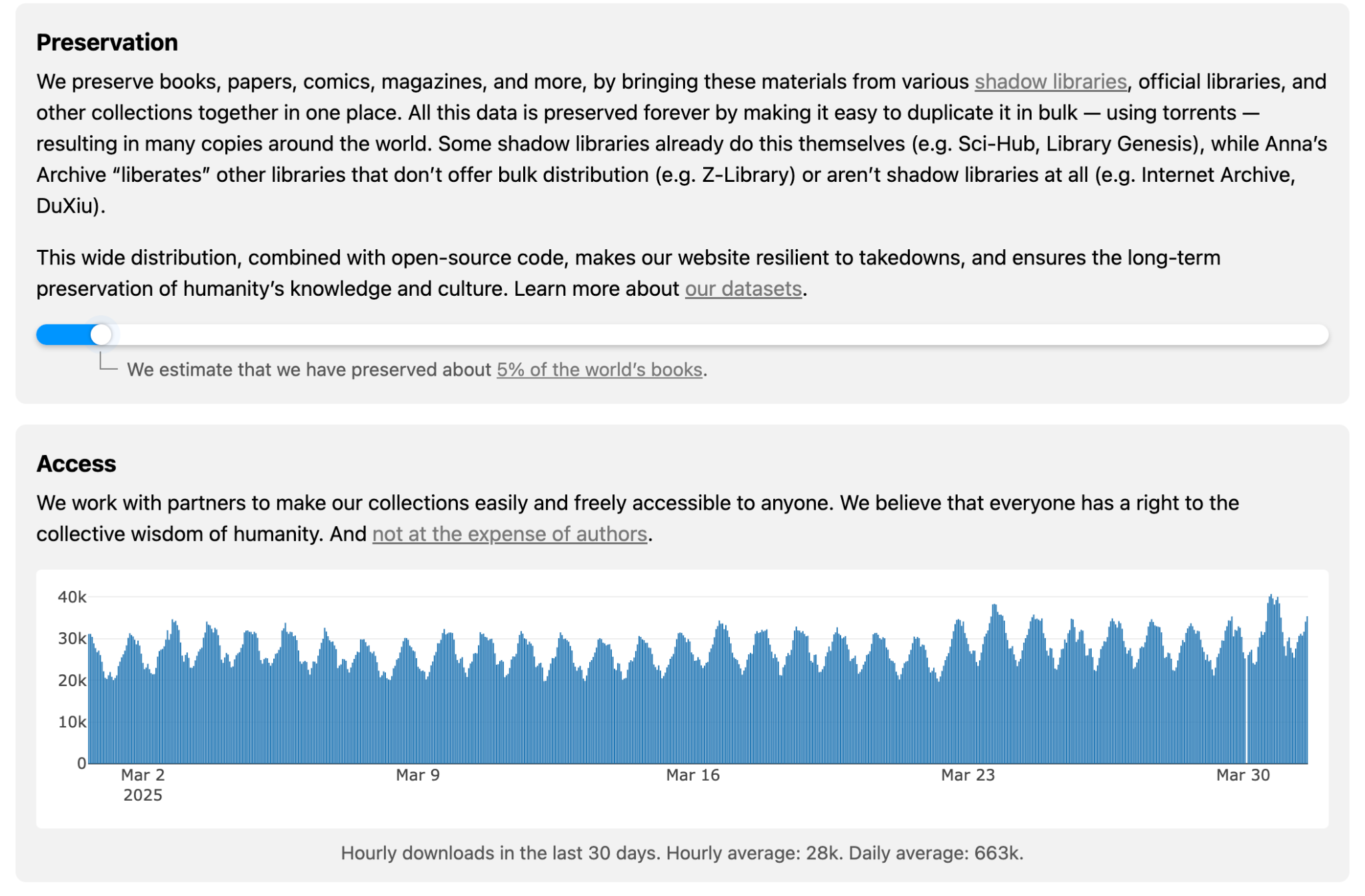
Come detto, l’obiettivo finale di Anna non è solo quello di fondare una biblioteca pubblica, ma di creare una copia digitale dei libri esistenti online (idealmente di tutti i libri) per evitare che scompaiano. Un tracker ci tiene aggiornati in tempo reale su quanti libri sono già stati copiati. Questo materiale proviene per lo più da archivi online, ufficiali e non, che Anna chiama “Biblioteche ombra”. In questo senso, Anna’s Archive è per molti versi l’ultimo caso di una lunga storia di biblioteche online.
Il termine “Biblioteca ombra” ha una doppia e contraddittoria definizione. La prima è quella di grandi database di testi scritti che sono archiviati in modo non open-access, come ad esempio la biblioteca di JStor. “Ombra”, in questo senso, significa che l’utente può conoscerne l’esistenza, perché i testi possono essere trovati, ad esempio, con uno strumento di ricerca, ma, come nell’ombra, il contenuto è nascosto (accessibile solo a chi passa per canali istituzionali che pagano abbonamenti al servizio). La seconda definizione, la più usata, di “Biblioteca ombra” è un grande archivio digitale che raccoglie e distribuisce materiale scritto (documenti accademici, libri) e talvolta altri media, violando le leggi sul copyright vigenti in alcuni paesi. In questo caso, il termine “ombra” significa “illegale”; con lo stesso significato, viene usata la formula “Black Open Access” (Black OA). Secondo la prima definizione, forse la più grande biblioteca ombra su Internet è Google Libri, che ha avuto origine da un massiccio progetto di digitalizzazione di libri del 2004 che ha coinvolto cinque importanti biblioteche accademiche negli Stati Uniti. Nei primi quattro anni, doveva essere una biblioteca digitale universale, ma nel 2008 le questioni relative al copyright ne hanno bloccato l’accesso, che ora è soggetto a sottoscrizione, anche per le stesse biblioteche che quei libri hanno fornito.
Un altro importante progetto da menzionare in questo contesto è Internet Archive, il precursore di molte moderne Biblioteche ombra, (anche se Anna indica direttamente che non lo riconosce sotto questa definizione). Fondato inizialmente nel 1996 come mezzo per fornire “accesso universale a tutte le conoscenze”, Internet Archive è partito dal presupposto che una vasta gamma di pagine fossero scritte e prodotte attraverso il web, e che nessuno si preoccupava di preservare. Questo ha portato alla creazione della Wayback Machine, un potente strumento ancora disponibile online che registra tutte le pagine web del passato. Lentamente, l’archivio ha iniziato a raccogliere libri e altri contenuti multimediali, diventando una biblioteca di un nuovo tipo: la maggior parte del materiale non era disponibile per il download, ma gli utenti potevano leggerlo online. Grazie a uno speciale sistema di prestito, Internet Archive offriva accesso a molti libri (secondo fonti ufficiali, all’inizio del 2022 ne aveva più di 35 milioni), rispettando teoricamente le leggi sul copyright. Internet Archive aspira a essere una biblioteca online legale. Tuttavia, nel 2020, Internet Archive è stata citata in giudizio da quattro giganti dell’editoria in lingua inglese (Hachette, Penguin, HarperCollins, John Wiley), e l’esito è stato una notevole riduzione dell’accessibilità dei suoi contenuti. Questo caso rende evidente quanto sia controverso il concetto di prestito nel regime dell’attuale legge sul copyright. Mentre in una biblioteca fisica un utente può prendere in prestito qualsiasi libro, in una biblioteca digitale il prestito è vietato se le copie elettroniche sono in vendita. Questo fatto suggerisce che ciò che prevale non è una definizione chiara di accessibilità e utilizzo dei contenuti, ma solo se la pratica del prestito e della diffusione influisca o meno sui profitti economici delle case editrici. Internet Archive, che ha l’ambizione di essere un’istituzione culturale innovativa, sta lottando per trovare uno statuto riconosciuto all’interno di questo quadro fortemente distorto, costantemente tenuto sotto controllo dalle mutevoli normative sul copyright.
Parallelamente a queste grandi imprese, che provengono dalla cultura della Silicon Valley, esiste una storia non meno rilevante delle biblioteche online post-sovietiche. In una delle migliori ricerche pubblicate sul tema delle biblioteche ombra, Shadow Libraries: Access to Knowledge in Global Higher Education, Balázs Bodó ricostruisce la storia della creazione di tali archivi condivisi all’interno della cultura e della controcultura sovietica. Bodó suggerisce che le biblioteche pirata russe siano emerse da questo intreccio di fattori:
...Communist ideologies of the reading nation and mass education; the censorship of texts; the abused library system; economic hardships and dysfunctional markets; and, most importantly, the informal practices that ensured the survival of scholarship and literary traditions under hostile political and economic conditions (Bodó 2018, 33).
Fin dall’inizio, il copyright sovietico era molto diverso da quello occidentale: la questione della garanzia di entrate per i privati era inesistente e tutti gli editori, gli studi cinematografici, ecc. erano di proprietà statale, il che significava che la maggior parte dei libri e dei film erano apertamente accessibili o disponibili a un prezzo molto basso (e così è ancora oggi). In secondo luogo, il grande laboratorio della controcultura sovietica sviluppò una serie di pratiche per distribuire materiale censurato, dall’autopubblicazione (samizdat) alla condivisione di biblioteche e mezzi fai-da-te di copia e distribuzione. L’era di Internet ha visto una continuazione di queste pratiche e i primi archivi condivisi online hanno iniziato a essere messi online da scienziati e utenti di lingua russa, che collettivamente digitalizzavano libri a mano, scaricavano gli archivi degli istituti di ricerca in cui lavoravano, setacciavano Internet per formattare e organizzare biblioteche che avrebbero raggiunto decine di migliaia di titoli: Lib.ru (1994) di Maxim Moshkov, Kolkhoz (2002), Monoscop, Gigapedia (anni 2000). Ciascuna di queste biblioteche era in qualche modo collegata alle altre. Poi è arrivato il tempo della diffusa Library.ru (2010), che è stata citata in giudizio nel 2012 e chiusa, e di Library Genesis (2007), che ha raccolto il set di dati di Library.ru. Si può quindi affermare che la controcultura sovietica – e la carenza post-sovietica di distributori ufficiali ben forniti – abbiano influenzato lo sviluppo di quelle che sarebbero poi diventate le biblioteche pirata, esplorando e sviluppando i percorsi di raccolta, organizzazione e ampia diffusione della conoscenza, e ciò approfittando della scarsa applicazione del copyright nei primi anni del World Wide Web.
Anna è per molti versi la continuazione di una serie di numerose Biblioteche ombra e dichiara apertamente di essere stata ispirata da Library Genesis. D’altra parte, l’ambizione dei suoi obiettivi si è alzata. LibGen non intende contenere tutto, ma i suoi confini sono creati in dialogo con la comunità, misurati dall’atto di digitalizzare e condividere attivamente i libri e mantenere un profilo basso (Bodó 2018, 36). Anna’s Archive vuole invece creare una biblioteca universale che includa e conservi possibilmente tutti i libri del mondo, e lo fa con coraggio. In altre parole, Anna propone un progetto che non ha eguali in termini di dimensioni e ambizioni. In questo contesto, Anna è forse una delle poche biblioteche online, indipendentemente dal loro status giuridico, che persegue l’obiettivo della Biblioteca universale, e che, inoltre, funziona su base completamente non-profit: il lavoro del team è per lo più volontario e il finanziamento proviene da donazioni degli utenti e da iscrizioni: i proventi che così entrano servono ad aumentare la velocità di download. Probabilmente, il budget di Anna è molto inferiore a quello di qualsiasi grande biblioteca del mondo. Tuttavia, Anna ha imparato da LibGen che la conservazione della cultura intellettuale, in questo caso dei libri, nell’aggressivo ambiente giuridico e online contemporaneo, implica la necessità di creare il maggior numero possibile di copie, in modo che in caso di perdita di una singola biblioteca, le copie esistano altrove. Queste copie dell’archivio sono chiamate “mirror”. Qualsiasi utente può non solo scaricare singoli libri, ma creare un’intera copia di Anna, copiandone il codice open source. Oggi, la più grande biblioteca di scienze umane richiede un petabyte (un milione di gigabyte) di memoria, più o meno la stessa quantità di dati generati in un mese di riprese di una serie Netflix.
Oggi, oltre ad Anna, c’è un altro sistema che può essere in qualche modo ricollegato all’esperienza post-sovietica di condivisione dei dati, che passa attraverso una funzione speciale integrata nel messenger del social network più popolare in Russia, VKontakte. Essendo essenzialmente una versione russa di Facebook, ha la reputazione di essere uno dei siti pirata più affidabili, dato che utilizza un sistema di circolazione di file privati. In altre parole, anche un libro o un articolo inviato in messaggi privati può essere trovato da un utente terzo nella sua ricerca di file. Pertanto, la procedura per caricare dati è praticamente incontrollata e non ricade sulle spalle di un piccolo team di volontari, come l’Archivio di Anna, ma è un’operazione costante che coinvolge tutti gli utenti di Internet. In questo caso, il controllo totale è quasi impossibile, perché la circolazione dei dati è spontanea. È un esempio di come, a volte la forza collettiva di milioni di utenti possa sconfiggere le restrizioni imposte dall’alto.
E qui si pone inevitabilmente la questione del copyright. Negli ultimi decenni, le leggi sul copyright hanno limitato severamente le condizioni di utilizzo e di accesso alle informazioni e al lavoro creativo, con poca o nessuna considerazione per gli obiettivi perseguiti da un particolare progetto e il suo finanziamento. Il significato delle “Biblioteca ombra” in questo contesto diventa qualcosa di più della semplice designazione di un fenomeno di pirateria: si tratta di un segnale di resistenza a standard di copyright obsoleti, e alla riformulazione del concetto di cosa sia una biblioteca. “Ombra” per Anna è in qualche modo omologa all’ “underground” sovietico. Anna è l’“underground” del copyright, le cui norme si sforzano di farla cessare di esistere. Questo è chiaro se leggiamo il primissimo post della neonata Anna, quando Anna non era ancora Anna, ma la “Pirate Library Mirror”, nel giugno 2022:
Introducing the Pirate Library Mirror (EDIT: moved to Anna’s Archive): Preserving 7TB of books (that are not in Libgen)
This project aims to contribute to the preservation and libration of human knowledge. We make our small and humble contribution, in the footsteps of the greats before us.
The focus of this project is illustrated by its name:
Pirate – We deliberately violate the copyright law in most countries. This allows us to do something that legal entities cannot do: making sure books are mirrored far and wide;
Library – Like most libraries, we focus primarily on written materials like books. We might expand into other types of media in the future;
Mirror – We are strictly a mirror of existing libraries. We focus on preservation, not on making books easily searchable and downloadable (access) or fostering a big community of people who contribute new books (sourcing) (https://annas-archive.org/blog/blog-introducing.html).
[Presentazione della Pirate Library Mirror (EDIT: spostato nell’archivio di Anna): Conservazione di 7 TB di libri (che non sono in Libgen)
Questo progetto mira a contribuire alla conservazione e alla liberazione della conoscenza umana. Diamo il nostro piccolo e umile contributo, seguendo le orme dei grandi che ci hanno preceduto. Il fulcro di questo progetto è illustrato dalla storia del suo nome:
Pirate (pirata) – Violiamo deliberatamente la legge sul copyright nella maggior parte dei paesi. Questo ci permette di fare qualcosa che le istituzioni legali non possono fare: assicurarci che i libri siano replicati quanto più possibile in quantità e in diffusione.
Library (biblioteca) – Come la maggior parte delle biblioteche, ci concentriamo principalmente su materiali scritti come i libri. In futuro potremmo espanderci ad altri tipi di media.
Mirror (Specchio) – Siamo esclusivamente uno specchio delle biblioteche esistenti. Ci concentriamo sulla conservazione, sul rendere i libri facilmente ricercabili e scaricabili (accesso) e sul promuovere una grande comunità di persone che contribuiscono all’archivio con nuovi libri (approvvigionamento) (https://annas-archive.org/blog/blog-introducing.html).
Il nome Pirate Library Mirror ha un valore precisamente tecnico e sintetizza le basi su cui è stata fondata Anna. All’inizio, Anna era principalmente un dispositivo creato in aperto contrasto con le leggi sul copyright, considerate dannose per il valore più importante della conservazione della conoscenza, da cui il nome “Pirata”. “Biblioteca” è semplicemente perché l’obiettivo della conservazione è il materiale scritto e i libri. Il metodo di questo contrasto è il mirroring, la creazione di copie ridondanti che rendono difficile il tracciamento dei servizi di hosting e consentono la resilienza in caso di arresto del server – da cui il nome “Mirror”. Questa scelta, d’altro canto, ha comportato che il sistema debba essere leggero sia in termini di servizi, il che significa nessun strumento per interagire con i dati stessi (strumenti di ricerca, ecc.), sia con gli utenti (la rete comunitaria), caratteristiche che sono ad esempio presenti nell’Internet Archive e che sono quasi considerate una merce nell’Internet contemporaneo. Tuttavia, la semplicità e la brusca franchezza di Anna è ciò che la rende unica e che merita un ulteriore approfondimento.
La retorica di Anna: semplice e radicale
Il blog di Anna ha una grafica minimale: un’intestazione gialla, un grande titolo in Comic Sans, che ricorda i primi blog su Internet negli anni Novanta. Ci sono solo poche pagine, che vanno dal giugno 2022 ad oggi, che sono in realtà la fonte migliore per tracciare lo sviluppo del progetto. Tutto, dall’aspetto grafico allo stile di scrittura, ci dice che Anna vuole essere semplice, concentrata su pochi compiti e diretta. Anna ha sostituito il meno attraente e anonimo Pirate Library Mirror, e ci dice qualcosa sull’importanza di un nome:
One decision to make for each project is whether to publish it using the same identity as before, or not. If you keep using the same name, then mistakes in operational security from earlier projects could come back to bite you. But publishing under different names means that you don't build a longer lasting reputation. We chose to have strong operational security from the start so we can keep using the same identity, but we won't hesitate to publish under a different name if we mess up or if the circumstances call for it.
In some way, the name is the only thing that keeps the library unified, a holdfast. Books and files can be mirrored everywhere, but if we want to make a statement, at the end, it is necessary to fix a point, create an identity that can engage in a debate.
[Una decisione da prendere per ogni progetto è se pubblicarlo usando la stessa identità di prima o meno. Se si continua a usare lo stesso nome, gli errori nella sicurezza operativa dei progetti precedenti potrebbero ritorcersi contro. Ma pubblicare con nomi diversi significa non costruirsi una reputazione più duratura. Abbiamo scelto di avere una forte sicurezza operativa fin dall’inizio in modo da poter continuare a utilizzare la stessa identità, ma non esiteremo a pubblicare con un nome diverso se commettiamo errori o se le circostanze lo richiedono.
In un certo senso, il nome è l’unica cosa che mantiene unita la biblioteca, il punto fermo. Libri e file possono essere duplicati ovunque, ma se vogliamo fare una dichiarazione, alla fine, è necessario fissare un punto, creare un’identità che possa impegnarsi in un dibattito].
La necessità di un nome riconoscibile, nonostante le preoccupazioni per la visibilità e la sicurezza, rivela il fatto che Anna vuole lasciare un segno nella storia della circolazione della conoscenza. Come afferma, è un “appiglio”, un “punto fermo”, un’“identità” che può impegnarsi in un dibattito. Il nome Anna è un nome biblico, il nome della regina che nel 1710 inventò il copyright, un palindromo, ma potrebbe anche essere il nome comune di un lettore qualsiasi, in modo simile a quello che Caroline was for the journal Queen, che ha dato il nome al famoso pirata offshore Radio Caroline (Pedersoli, Toson 2020). Il nome stesso induce la domanda – Chi è Anna?, a cui la pronta risposta è: – Tu sei Anna! Un nome comune, come molti nomi comuni utilizzati nel marketing e nel branding, che vuole creare complicità e, forse, identificazione con l’utente. Leggendo il blog e vedendo lo sviluppo dell’Archivio di Anna negli ultimi anni, è chiaro che, nonostante l’anonimato iniziale del progetto, che sembrava interessarsi solo agli aspetti tecnici della sfida al blocco, Anna è diventata progressivamente più consapevole di sé, sviluppando una personalità e uno stile davvero unici.
Ad esempio, Anna non ha una pagina “About”, dove dichiara chi è, chi sono i fondatori, quali sono le loro idee politiche, ecc. Invece, ha una pagina FAQ di rilievo, che pare costituire un genere letterario a sé stante. È costruita come una lunga intervista fatta con le domande ricevute dagli utenti: la prima domanda è – “Come posso aiutarti?”. La maggior parte delle domande spiegano gli aspetti tecnici della piattaforma, ma leggendo tutta la pagina delle FAQ è possibile avere una visione abbastanza dettagliata e comprensiva di come funziona Anna: download, donazioni, codice sorgente. Allo stesso tempo, ci sono stranezze che fanno emergere la personalità di Anna: “Ho scaricato 1984 di George Orwell, la polizia verrà a bussare alla mia porta?”; – Chi è Anna? – Tu sei Anna! Ma forse la cosa più sorprendente è la lista di libri che compare alla fine:
What are your favorite books?
Here are some books that carry special significance to the world of shadow libraries and digital preservation:
Michele Boldrin, David K. Levine, Against intellectual monopoly;
Stephenson, Neal, Cryptonomicon;
Aaron Swartz, The Boy Who Could Change the World : The Writings of Aaron Swartz;
Witt, Stephen R, How Music Got Free : A Story of Obsession and Invention;
А. М. Прохоров, Физическая энциклопедия. Ааронова – Длинные Том 1.
Swartz, Boldrin, Levine, Witt sono tra i nomi più importanti del movimento Copyleft e definiscono chiaramente il quadro chiaro in cui Anna sta operando e in qualche modo esprimono una visione politica (anche se Anna afferma in più punti di non essere interessata alla politica). Il team di Anna’s Archive, come nel libro di Boldrin e Levine, critica il sistema obsoleto del copyright, affermando che a causa della semplificazione dell’accesso alla conoscenza nel mondo moderno, molti requisiti dovrebbero essere modernizzati, come ad esempio il periodo di scadenza di 70 anni dei diritti d’autore, molto più lungo del limite dei brevetti, che dura 20 anni. In altre parole, direttamente o indirettamente, pur rifiutandosi di affrontarlo nel concreto/direttamente, Anna è impegnata nel dibattito sulla legge sul copyright, suggerendo miglioramenti e sfidando l’idea che solo il profitto dal monopolio intellettuale possa produrre qualità. Progetti open source come Wikipedia o Linux, o la stessa Anna, dovrebbero essere una dimostrazione sufficiente che è possibile anche il contrario.
Oltre alla discussione sul copyright, la radicalità di Anna deriva dal disprezzo e dalla sfiducia delle istituzioni nel compito più importante di preservare la conoscenza e condividerla con le generazioni future:
Humanity largely entrusts corporations like academic publishers, streaming services, and social media companies with this heritage, and they have often not proven to be great stewards.
There are some institutions that do a good job archiving as much as they can, but they are bound by the law. As pirates, we are in a unique position to archive collections that they cannot touch, because of copyright enforcement or other restrictions. We can also mirror collections many times over, across the world, thereby increasing the chances of proper preservation (https://annas-archive.org/blog/blog-how-to-become-a-pirate-archivist.html).
[L’umanità affida in gran parte questo patrimonio a società come editori accademici, servizi di streaming e aziende di social media, che spesso non si sono dimostrati ottimi amministratori.
Ci sono alcune istituzioni che fanno un buon lavoro di archiviazione per quanto possibile, ma sono vincolate dalla legge. Come pirati, siamo in una posizione unica per archiviare collezioni che non possono toccare, a causa dell’applicazione del copyright o di altre restrizioni. Possiamo anche duplicare le collezioni più volte, in tutto il mondo, aumentando così le possibilità di una corretta conservazione (https://annas-archive.org/blog/blog-how-to-become-a-pirate-archivist.html).
La semplicità di Anna e la sua attenzione agli aspetti tecnici della conservazione ci obbligano a riflettere sulla reale efficacia e utilità delle istituzioni pubbliche.
La cultura della sfiducia nei confronti di aziende, istituzioni, governi e leggi riflette una crisi generale che è iniziata con il grande crollo finanziario del 2008 e i movimenti Occupy Wall Street. Quella sfiducia nei confronti delle istituzioni finanziarie ha portato rapidamente alla diffidenza nei confronti di tutto ciò che in qualche modo era collegato ad esse, e in particolare verso le istituzioni accademiche, soprattutto del mondo anglosassone. Negli stessi anni di Library Genesis sono state create le prime criptovalute, sviluppate in risposta a un sistema finanziario ritenuto inaffidabile. L’idea principale, sia nelle Biblioteche ombra che nelle criptovalute, è quella di decentralizzare il controllo e la distribuzione della valuta così come delle informazioni scritte. Fondamentalmente, ed è ciò che fa la differenza, è la tecnologia di distribuzione e conservazione dei dati o della valuta, basata su reti sparse e registri ridondanti, piuttosto che su sistemi centralizzati. Questa è stata la spinta principale che ha portato allo sviluppo della tecnologia blockchain, ideata appositamente per evitare la necessità di un’istituzione centrale come una banca per emettere e regolare la valuta. In entrambi i casi, per la criptovaluta e per l’Archivio di Anna, c’è una sfiducia latente nelle istituzioni che sembrano essere sempre più instabili. I recenti episodi bellici e le sanzioni che hanno paralizzato la globalizzazione, come l’esclusione delle banche russe dal sistema SWIFT, hanno dimostrato come la criptovaluta possa essere efficace nell’evitare le limitazioni imposte dallo Stato, garantendo l’anonimato e consentendo a centinaia di migliaia di rifugiati di trasferirsi in paesi stranieri. Anna utilizza principalmente criptovalute nelle sue transazioni. L’anonimato sistemico e la tecnologia peer-to-peer/blockchain sembrano essere gli strumenti per contrastare il crescente autoritarismo globale.
Dietro la semplicità grafica e comunicatiiva, Anna implementa un sistema tecnicamente avanzato per archiviare la biblioteca su diversi server e renderla accessibile attraverso molteplici percorsi. Ma un approccio semplice può anche essere la risposta alla necessità di comunicare in modo completamente globale e interculturale, trattando pubblicazioni che spaziano da pubblicazioni scientifiche cinesi alla poesia canadese. La radicalità e il successo di Anna risiedono nella sua leggerezza e nella chiarezza nella mediazione tra produttori e consumatori di conoscenza. Da questo punto di vista, può sembrare quasi provocatorio e difficile da accettare, poiché noi come utenti di contenuti multimediali siamo stati abituati a grafiche e servizi elaborati. Inoltre, l’approccio generale di una curatela evanescente è antitetico al classico mondo accademico e culturale occidentale, dove istituzioni pesanti creano sistemi pesanti e culturalmente inquadrati per l’archiviazione e la diffusione della conoscenza.
Anna, sottofinanziata e illegale in molti paesi, senza un consiglio di amministrazione o un comitato scientifico, ci costringe a ripensare e a mettere in discussione l’efficacia di tali istituzioni nel mondo moderno. Com’è possibile che Anna sia in grado di dare accesso alla conoscenza a molte più persone e in un modo molto più equo ed efficiente di chiunque altro? La sua esistenza ci fa sospettare che le sovrastrutture di tali istituzioni non siano interessate a sviluppare la conoscenza umana, ma piuttosto a gestirla per porla sotto l’influenza di altri poteri. Nel migliore dei casi, semplicemente non sono abbastanza efficienti. Anna separa la conoscenza dalla cultura, preferendo la prima, come afferma chiaramente:
Per megabyte of storage, written text stores the most information out of all media. While we care about both knowledge and culture, we do care more about the former (https://annas-archive.org/blog/critical-window.html).
[Mediante megabyte di memoria, il testo scritto memorizza la maggior parte delle informazioni di tutti i media. Anche se ci interessano sia la conoscenza che la cultura, ci interessa di più la prima (https://annas-archive.org/blog/critical-window.html)].
Visualizzazione parlante di Anna
La radicale essenzialità di Anna la porta naturalmente alla ricerca di una rappresentazione di sé in modo conciso. Non è un compito facile. Anna è una biblioteca che vuole raccogliere tutti i libri del mondo, in un modo che ricorda i libri e le biblioteche di Borges ed Eco. Umberto Eco immaginava una biblioteca in cui ogni libro era composto da quattro numeri, uno per la stanza, uno per la parete, uno per lo scaffale e l’ultimo per la posizione nello scaffale. Questi quattro numeri incorporerebbero molte delle informazioni sulla biblioteca stessa: ad esempio, il secondo numero direbbe qualcosa su quante pareti ci sono nelle stanze. Quando immaginiamo di archiviare la conoscenza, l’arte combinatoria emerge come una costante. Anna non fa eccezione a questo gioco.
Recentemente, sul blog di Anna, c’è stato un concorso a premi per chi avesse rappresentato nel modo migliore e più elegante tutti i libri pubblicati, come lo chiamano loro, una “To-Do-List of Human Knowledge” (Lista delle cose da fare sulla conoscenza umana). Come Eco, il personaggio principale di questa rappresentazione è un numero, ma composto da 13 cifre: il comune ISBN (International Standard Book Number), introdotto nel 1970, definisce la singola edizione di un libro. Come i numeri di Eco, gli ISBN sono divisi in parti, la prima, 978, che significa “questo è un ISBN”, e le successive, che definiscono il gruppo (un paese o un’area linguistica), l’editore, il libro. È un sistema comodo per la gestione della logistica del libro inteso come prodotto, allo stesso modo in cui altri codici a barre definiscono la salsa di pomodoro o la carta igienica al supermercato. Gli ISBN sono semplicemente numeri con un prefisso e coprono un massimo di 2 miliardi di libri. È un numero enorme, molte volte superiore a tutti i libri pubblicati fino ad oggi, e una rappresentazione grafica di tutti gli ISBN è il primo passo per una visualizzazione complessiva di quanto di scritto ha prodotto la conoscenza umana.
Nel descrivere gli obiettivi del concorso, Anna ha pubblicato la visualizzazione più semplice: un grande quadrato in cui ogni pixel rappresenta ogni possibile ISBN, in ordine progressivo. I pixel neri sono numeri non ancora assegnati, quelli bianchi sono libri pubblicati. L’immagine è già di per sé piuttosto rivelatrice: vediamo uno schema criptico con migliaia di segmenti sottili di diverse lunghezze, che vanno dalla larghezza completa del quadrato a pochi pixel, coprendo in modo non uniforme lo spazio. Tutti i libri scritti dagli esseri umani dall’invenzione della scrittura a oggi non sono solo altro che una una rada costellazione nello spazio oscuro di tutti i libri possibili. Le linee e i segmenti ricordano un complesso problema combinatorio che coinvolge insiemi e sottoinsiemi di un insieme più grande, ma in realtà sono il prodotto dell’amministrazione umana, una combinazione di regolarità e casualità su scale diverse. I numeri sono assegnati in grandi blocchi, circa 100 milioni, a diversi paesi, che poi decidono per conto loro come distribuirli. Quindi, possiamo vedere la costellazione rompersi a intervalli più o meno regolari, e poi gli intervalli stessi divisi in modi diversi, a volte regolarmente, a volte no, a volte su una scala più grande, a volte su una più piccola, in strutture frattali. In questa immagine la biblioteca dell’umanità non è una semplice fila di libri, che riempie scaffale dopo scaffale come potremmo vedere in una biblioteca fisica, o in quelle immaginate da Eco e Borges, ma piuttosto uno spazio disordinato e per lo più vuoto – un cielo vuoto che pare quasi disturbato dalla presenza dei libri.

Il problema principale di questa rappresentazione è che riempie lo spazio in righe e singoli gruppi di libri, come: ad esempio tutta la letteratura brasiliana è assottigliata in un segmento orizzontale alto solo un pixel.
Per ovviare a questo, una delle proposte vincenti cerca di disporre la linea del numero ISBN in modo che i numeri vicini possano formare un’area a due dimensioni. Per ottenere questo risultato, viene utilizzata una curva di riempimento dello spazio, uno speciale dispositivo matematico che deriva dai percorsi di tassellazione dello spazio di Peano, sviluppati per affrontare il problema della misurabilità dell’infinito.

La linea si snoda nel piano delineando diversi gruppi in aree simili a quelle di una mappa geografica, con sinuosi contorni frattali come in una ideale linea costiera. Ogni pixel colorato all’interno delle forme rappresenta un libro pubblicato. Diversi paesi, di dimensioni progressivamente più piccole, sono annidati l’uno nell’altro. Le forme sono complesse e uniche e ci danno un’idea visiva della quantità di libri pubblicati in ogni lingua. L’inglese è di gran lunga la lingua più numerosa. La precedente costellazione sparsa si è condensata in una geografia unica della conoscenza umana, non basata sulla classificazione tradizionale (come la classificazione Dewey nelle biblioteche classiche), ma secondo un insieme arbitrario di regole e la loro visualizzazione matematica. Come nell’immagine precedente, i continenti dei libri sono più simili ad arcipelaghi immersi in un mare oscuro, ma possiamo iniziare a confrontarli e vedere, come in una gigantesca mappa di Risiko, quali continenti siano più potenti nella produzione di libri. Non sorprende che le proporzioni siano poco diverse dalle loro controparti geopolitiche.
La seconda proposta che ha vinto il premio, è invece molto più ordinata, più simile alle biblioteche immaginarie di Borges ed Eco, con libri disposti su scaffali virtuali regolari, disposti in librerie regolari, disposte in gruppi regolari e così via, in una progressione di insiemi sempre più grandi. In questo caso, i gruppi non creano diverse forme ad incastro, ma stanno in una griglia di rettangoli della stessa misura, con diversi livelli di riempimento. La precedente geografia frattale della conoscenza umana è stata sostituita da una tabella impersonale, ma più rassicurante, abbastanza ordinata da trovare tutto ciò che stiamo cercando, ma anche inquietante nella rigidità della griglia, simile a una città ippodamea infinita in cui gli appezzamenti vengono lentamente ma inesorabilmente sfruttati fino che ce ne sarà uno disponibile.
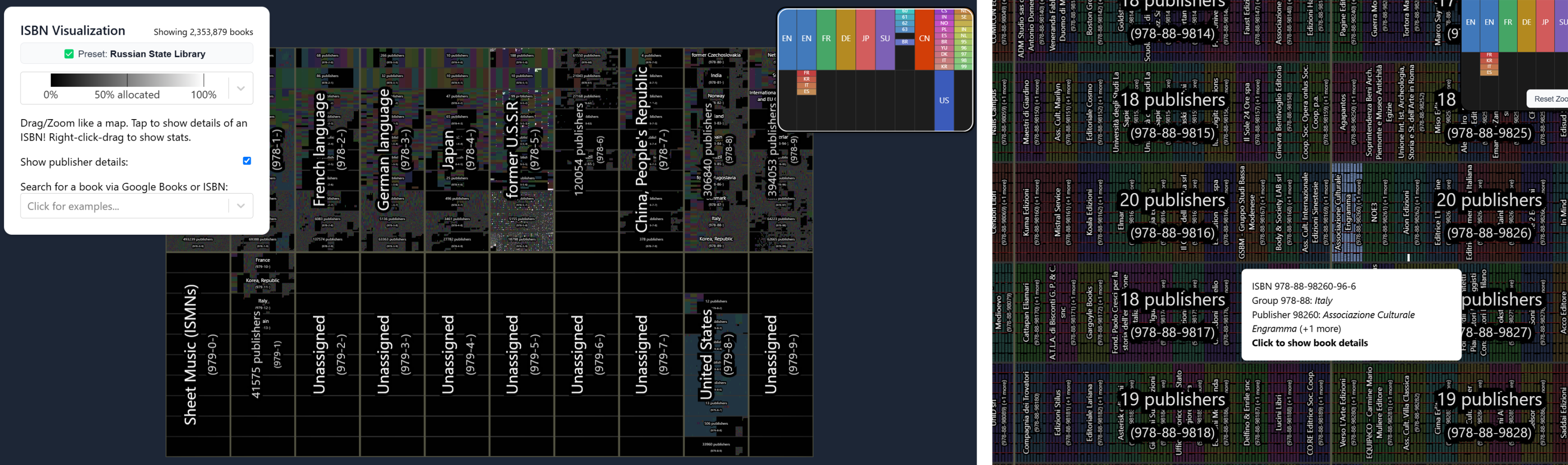
Questi sono solo i primi tentativi di quello che sembra essere un esercizio molto complesso di visualizzazione dei dati, ma l’Archivio di Anna è una delle poche biblioteche che sta cercando di provare a proporre una tale visualizzazione. Questi esercizi di rappresentazione di una sobria “lista di cose da fare” stanno effettivamente sollevando la questione fondamentale di cosa sia oggi una biblioteca o un archivio. Rappresentare tutti i libri rende la conoscenza umana in un certo senso sorvegliabile, accessibile, a prima vista controllabile. Ma poi, entrando nei dettagli di queste rappresentazioni, siamo sopraffatti dalla densità della loro struttura interna, dalle ricorsività intricate e irregolari.
Man mano che le biblioteche diventano più grandi, il metodo della loro rappresentazione, la struttura del loro archivio, diventa la biblioteca stessa. È l’arte combinatoria dei suoi elementi che la rende comprensibile e navigabile, come nelle visioni di Eco e Borges. E forse Anna è più bizzarra e complessa di quanto quei maestri di sapere avrebbero mai immaginato per una biblioteca universale. Ma contemporaneamente essendo Anna una biblioteca utopica per il futuro, è una forma di realizzazione del loro sogno.
Anna e l’intelligenza artificiale
La biblioteca universale nella sua rappresentazione e consistenza sembra infinita e travolgente per una mente umana, è tuttavia limitata nel numero, il che significa che può essere scansionata e manipolata con l’aiuto di grandi modelli linguistici (LLM). Anna si è resa conto abbastanza presto che il suo archivio sarebbe stato una risorsa estremamente preziosa per la formazione degli LLM:
This is a short blog post. We’re looking for some company or institution to help us with OCR and text extraction for a massive collection we acquired, in exchange for exclusive early access. After the embargo period, we will of course release the entire collection.
High-quality academic text is extremely useful for training of LLMs. While our collection is Chinese, this should be even useful for training English LLMs: models seem encode concepts and knowledge regardless of the source language. (https://annas-archive.org/blog/duxiu-exclusive.html)
[Questo è un breve post sul blog. Stiamo cercando un’azienda o un’istituzione che ci aiuti con l’OCR e l’estrazione di testo per una vasta raccolta che abbiamo acquisito, in cambio di un accesso esclusivo anticipato. Dopo il periodo di embargo, ovviamente rilasceremo l’intera raccolta.
Il testo accademico di alta qualità è estremamente utile per la formazione dei modelli linguistici grandi (LLM). Anche se la nostra raccolta è in cinese, dovrebbe essere utile anche per la formazione di LLM in inglese: i modelli sembrano codificare concetti e conoscenze indipendentemente dalla lingua di partenza (https://annas-archive.org/blog/duxiu-exclusive.html)].
Oggi l’intelligenza artificiale è diventata una risorsa strategica, utilizzata per l’analisi dei dati, la sicurezza e le applicazioni militari. Stiamo assistendo a una corsa agli armamenti in questo campo, e i modelli linguistici sono particolarmente utili nell’estrazione di informazioni dagli archivi. In un futuro non troppo lontano, qualsiasi utente sarà in grado di chiedere all’IA di recuperare, ordinare e riassumere tutte le informazioni rilevanti su un argomento specifico, cercandole nell’intera biblioteca mondiale. E questo sarebbe molto più affidabile e preciso dei modelli addestrati alla ricerca online. Più il modello viene addestrato a leggere i testi stampati a partire dal 1400, meglio sarà in grado di raccogliere informazioni e rispondere alle domande in modo indipendente.
Le attuali norme sul copyright non solo non sono adatte a questo nuovo scenario, ma sono addirittura potenzialmente pericolose, come afferma Anna:
Me and my team are ideologues. We believe that preserving and hosting these files is morally right. Libraries around the world are seeing funding cuts, and we can’t trust humanity’s heritage to corporations either.
Then came AI. Virtually all major companies building LLMs contacted us to train on our data. Most (but not all!) US-based companies reconsidered once they realized the illegal nature of our work. By contrast, Chinese firms have enthusiastically embraced our collection, apparently untroubled by its legality. This is notable given China’s role as a signatory to nearly all major international copyright treaties (https://annas-archive.org/blog/ai-copyright.html).
[Io e il mio team siamo ideologici. Crediamo che preservare e ospitare questi file sia moralmente giusto. Le biblioteche di tutto il mondo stanno subendo tagli ai finanziamenti e non possiamo nemmeno affidare il patrimonio dell’umanità alle aziende.
Poi è arrivata l’IA. Praticamente tutte le principali aziende che costruiscono LLM ci hanno contattato per addestrarci sui nostri dati. La maggior parte (ma non tutte!) delle aziende statunitensi ha riconsiderato la propria posizione una volta compresa la natura illegale del nostro lavoro. Al contrario, le aziende cinesi hanno accolto con entusiasmo la nostra raccolta, mostrandosi incuranti della sua legalità. Questo è degno di nota dato il ruolo della Cina come firmataria di quasi tutti i principali trattati internazionali sul copyright (https://annas-archive.org/blog/ai-copyright.html)].
La storia delle Shadow libraries cambierà presto grazie ai Large Language Model. Una delle principali difficoltà nell’addestrare le intelligenze artificiali è disporre di buoni database con informazioni affidabili. Questo è esattamente ciò che sono le Shadow libraries, enormi raccolte ben ordinate di materiale affidabile. Se alcune aziende possono avere libero accesso al prezioso archivio, mentre altre sono vincolate dalla legge sul copyright, le prime avrebbero un enorme vantaggio, in quanto possono addestrare i loro programmi con libri scritti da specialisti, mentre le seconde dovranno avvalersi di archivi limitati o di fonti inaffidabili e non omogenee provenienti dal web e dai social network. E questo è ciò che apparentemente sta accadendo con le aziende cinesi che addestrano le loro intelligenze artificiali con l’Archivio di Anna. E potrebbe anche segnare la fine delle biblioteche aperte e dell’Open Access in generale. In futuro, i paesi e le aziende potrebbero evitare di pubblicare in modo accessibile per ridurre il vantaggio della concorrenza. La Biblioteca Universale potrebbe diventare in futuro la Biblioteca Universale delle Macchine, e le Shadow libraries potrebbero limitare l’accesso completo per limitare lo sfruttamento da parte delle intelligenze artificiali.
Conclusioni
Mentre all’inizio del XX secolo la questione riguardava lo stato di un’opera d’arte nell’era della riproduzione tecnica, ora, nel XXI secolo, ci troviamo di fronte a una reazione. Un processo simile sta avvenendo con la diffusione della conoscenza. Mentre in passato c’erano processi per l’introduzione dell’alfabetizzazione e dell’istruzione di massa, ora, con il pretesto di questioni di sicurezza o dei diritti dei singoli autori, stiamo assistendo a una certa tendenza a sospendere la distribuzione della conoscenza. Mettendoci dal punto di vista di Anna, si può parlare di una forma di reazione culturale, di un percorso verso l’elitizzazione della conoscenza, che sta diventando sempre più evidente. Cosa indica questo sintomo? Si tratta di tendenze nello sviluppo della scienza del futuro che diventeranno più evidenti in seguito? C’è qualche motivo per credere che la diffusione di massa della conoscenza non sia più necessaria? Ma allora cosa diventa una biblioteca? Qual è il ruolo di Anna in questo contesto?
Con queste condizioni, l’Archivio di Anna dovrebbe essere neutralizzato. Invece: radicalmente semplice, incredibilmente intricato nel suo funzionamento, rispecchiato in migliaia di copie, inafferrabile, apertamente anticulturale e anti-accademico, Anna reagisce al processo antidemocratico della diffusione del sapere, cercando di attirare l’attenzione sul sistema del controllo del copyright. Tuttavia, la reazione ai nuovi processi di autoritarismo globale non sta tanto nelle dichiarazioni e nei blog censurati e bloccati, quanto nel progetto stesso. Anna è una grande protesta contro ciò che sta accadendo. Anna è un vero e proprio sottosuolo di conoscenza, un’utopia che resiste alla minaccia delle realissime distopie che stiamo vivendo. Ma anche nella costruzione di una biblioteca ideale utopica del futuro, sorgono inevitabilmente domande antiche: Se ci si mette a copiare per salvare il sapere, da dove iniziare? Cosa è più importante? I libri? Gli articoli? I romanzi? Le opere scientifiche? Le opere di filosofia naturale o la letteratura antica? Anche un nuovo tipo di biblioteca non può evitare l’antico problema della gerarchia dei generi, anche se è rappresentata solo attraverso i codici ISBN. Anna, nella sua semplice radicalità, cerca di affrontare la questione nel modo più razionale possibile, inventando nuovi modi di supervisionare, cioè di rappresentare, tutti i libri di scienze umane. È il progetto che finora si è avvicinato di più alla creazione e alla rappresentazione di una biblioteca veramente universale – non più confinata nella fantasia di uno scrittore o di un intellettuale, ma come sistema di conservazione e distribuzione altamente tecnico, adatto a lavorare senza soluzione di continuità attraverso le culture globali.
Forse Anna non è un fenomeno culturale, forse è solo un sito pirata, un ennesimo strumento clandestino a uso di accademici e studenti. In ogni caso, anche se fosse solo un sito .torrent, tutti questi blocchi sono davvero necessari? È davvero necessario sanzionare le banche dati della conoscenza, create per lo più con ricerche finanziate con fondi pubblici? Ci sarà un effetto? E sarà un effetto inaspettato? Come accademici, speriamo egoisticamente che Anna sopravviva per qualche tempo sul fronte della sua lotta per il diritto alla conoscenza libera e raggiunga il traguardo di almeno il 10% di tutti i libri scaricati. E poi, forse, saremo in grado di avvicinarci un po’ di più alla risposta alle domande: – Cos’è Anna? – Chi è Anna?
Forse l’indizio migliore viene ancora una volta dalla peculiare bibliografia delle FAQ di Anna, dall’ultimo, e curiosamente strano libro, una vecchia enciclopedia sovietica di fisica (Prohorov 1988) che inizia in ordine alfabetico con l’effetto AAronov-Bohm, che ha lo stesso nome di Aaron Schwarz:
Quantum mechanic effect, characterised by the influence of an external electromagnetic field, concentrated in a region that is not accessible, on the quantum state of a charged particle (Prohorov 1988, 7).
[Effetto della meccanica quantistica, caratterizzato dall’influenza di un campo elettromagnetico esterno, concentrato in una regione non accessibile, sullo stato quantico di una particella carica (Prohorov 1988, 7)]
Un principio della fisica quantistica moderna afferma che possono verificarsi situazioni in cui le particelle sono influenzate da un campo anche se il campo è chiuso, a causa di un accoppiamento invisibile tra le funzioni d’onda e un potenziale elettromagnetico. È come l’attivismo di Aaron Schwarz che, anche quando è stato confinato e represso, è stato in grado di causare effetti all’esterno, nelle particelle/menti cariche che vanno oltre i principi comunemente accettati di localizzazione, e che possono agire globalmente, determinando uno “spostamento di fase”. Questo è l’effetto Anna.
Riferimenti bibliografici
- Adams 2025
C. Adams, Vanishing Culture: When Preservation Meets Social Media, Internet Archive Blogs, 9 April 2025. - Aiguo (2009).
L. Aiguo, Digitizing Chinese Books: A Case Study of the SuperStar DuXiu Scholar Search Engine, “Journal of Academic Librarianship”, 2009, 35, 277-281. - Anna 2022-2025 I
Anna’s Blog. - Anna 2022-2025 II
Anna’s Archive blog on Reddit. - Bodó 2018
B. Bodó, The Genesis of Library Genesis: The Birth of a Global Scholarly Shadow Library, in Karaganis et al. 2018, 25-51. - Boldrin 2008
M. Boldrin, D. K. Levine, Against Intellectual Monopoly, Cambridge, 2008. - Correa, Laverde-Rojas, Tejada, et al. 2022
J.C. Correa, H. Laverde-Rojas, J. Tejada, et al., The Sci-Hub effect on papers’ citations, “Scientometrics” 2022, 127, 99–126. - Karaganis et al. 2018
J. Karaganis (ed.), Shadow Libraries: Access to Knowledge in Global Higher Education, Boston 2018. - Pedersoli, Toson 2020
A. Pedersoli, C. Toson, Onde libere e rock ‘n’ roll. La rivoluzione delle emittenti offshore, “La Rivista di Engramma” n. 174, luglio/agosto 2020, 25-76. - Prohorov 1988
A.M. Prohorov, Fizicheskaya entsiklopediya. AAronova – Dlinnye tom 1, Moscow 1988. - Ruhenstroth 2014
M. Ruhenstroth, Schattenbibliotheken: Piraterie oder Notwendigkeit?, interview at Balázs Bodó, iRights info, 10 October 2014. - Rumfitt 2022
A. Rumfitt, In defence of Z-Library and book piracy, dazeddigital.com, November 2022. - Slum 2025
SLUM: The Shadow Library Uptime Monitor. - Stephenson 1999
N. Stephenson, Cryptonomicon, New York, 1999. - Swartz 2015,
Aaron Swartz, The Boy Who Could Change the World: The Writings of Aaron Swartz, New York, 2015. - Van der Sar 2025 I
E. Van der Sar, Pirate Libraries Are Forbidden Fruit for AI Companies. But at What Cost?, torrentfreak.com, 31 January 2025. - Van der Sar 2025 II
E. Van der Sar, Anna’s Archive Urges AI Copyright Overhaul to Protect National Security, torrentfreak.com, 1 February 2025. - Wikipedia 2025
Wikipedia page for Shadow library, accessed April 2025. - Witt 2015
S. R. Witt, How Music Got Free: A Story of Obsession and Invention, New York, 2015.
English abstract
This paper attempts to read Anna’ Archive in the context of the so called “Shadow Libraries”, and its effects on the global circulation of knowledge and the debate over copiright. Anna is the last of a long series of online repositories of shared written material that originated in the early years of the World Wide Web, especially in post-Soviet academic environments. Anna has a unique approach to digital preservation, based on a radical refusal of any law or insitution that limits the possibility of access and conservation of knowledge, encouraging the act of copying or mirroring her data. Anna’s style has developed from the beginning of the project, and has slowly developed a personality and a sophisticated work procedure. At the same time, Anna seems to seek a simple and radical approach, in order to act at a truly global scale. Anna is perhaps the only libary in the world that aspires to be universal, and is attempting to catalog and visualise the entire humanity’s written collection in innovative ways, that remind of the fictional libraries immagined by Borges and Eco, and questions us on what should be the real nature of a library in the future.
keywords | Anna’s Archive; universal library; shadow library; Intellectual property; Knowledge representation; AI training datasets.
la revisione di questo contributo è stata affidata al comitato editoriale e all’international advisory board della rivista
Per citare questo articolo / To cite this article: Elizaveta Kozina, Christian Toson, Anna, la libreria universale, “La Rivista di Engramma” n. 222, marzo 2025.